Soda Overview
Last modified on 26-Mar-25
Soda helps data teams build reliable data products and pipelines.
What Soda does
You can use Soda to test data as it flows through your pipelines and monitor data quality over time. Embed tests directly in your workflows or use Soda’s built-in observability features to detect and resolve data issues early.
Soda helps you answer key questions about your data:
- Is the data fresh?
- Is any data missing?
- Are there duplicate records?
- Did something go wrong during a transformation?
- Are all values within expected ranges?
- Are data quality metrics changing over time? Are there anomalies in freshness, row counts, or missing values?
How Soda approaches Data Quality
Soda follows two complementary approaches to managing data quality: data testing and data observability. Together, they help you prevent data issues and detect unexpected changes in production.
Data Testing
Data testing is a proactive approach to catch data quality issues before they impact downstream systems. It belongs early in your data lifecycle—during development, deployment, or transformation.
Use data testing to:
- Validate data during CI/CD workflows
- Compare source and target tables for reconciliation
- Check assumptions in transformation logic
- Enforce data contracts between teams and systems
Data tests are explicit, rule-based checks that you can define based on known expectations.
Data Observability
Data observability is a reactive approach to monitor data in production and catch unexpected issues as they emerge. It helps answer the question: What is happening with my data right now, and how is that changing over time?
Use data observability to:
- Detect anomalies in data quality metrics such as freshness, row counts, or null values
- Monitor metric trends and seasonality
- Identify late-arriving or missing records
- Get alerted when values deviate from historical norms
How Soda fits into your stack
Soda integrates with all major data platforms, including:
- Databases and data warehouses: BigQuery, Snowflake, Redshift, Databricks, PostgreSQL, Spark, Dask, PostgreSQL, Presto, DuckDB and more.
- Data catalog and metadata tools: Atlaion, Atlan, Collibra, data.world, Zeenea and more.
- Orchestration platforms: Airflow, Azure Data Factory, Dagster, dbt, Prefect and more.
- Cloud providers: AWS, Google Cloud, Azure.
- BI Tools: Looker, Tableua, PowerBi.
- Messaging and Ticketing: Jira, Opsgenie, PagerDuty, ServiceNow, MicroSoft Teams and Slack.
You can set up data quality tests programmatically using Soda Library, or configure them through the Soda Cloud user interface—without writing code. Test results are pushed to Soda Cloud for monitoring, collaboration, and alerting.
Soda’s deployment options
You can deploy Soda in three ways, depending on your team’s scale, security needs, and infrastructure preferences.
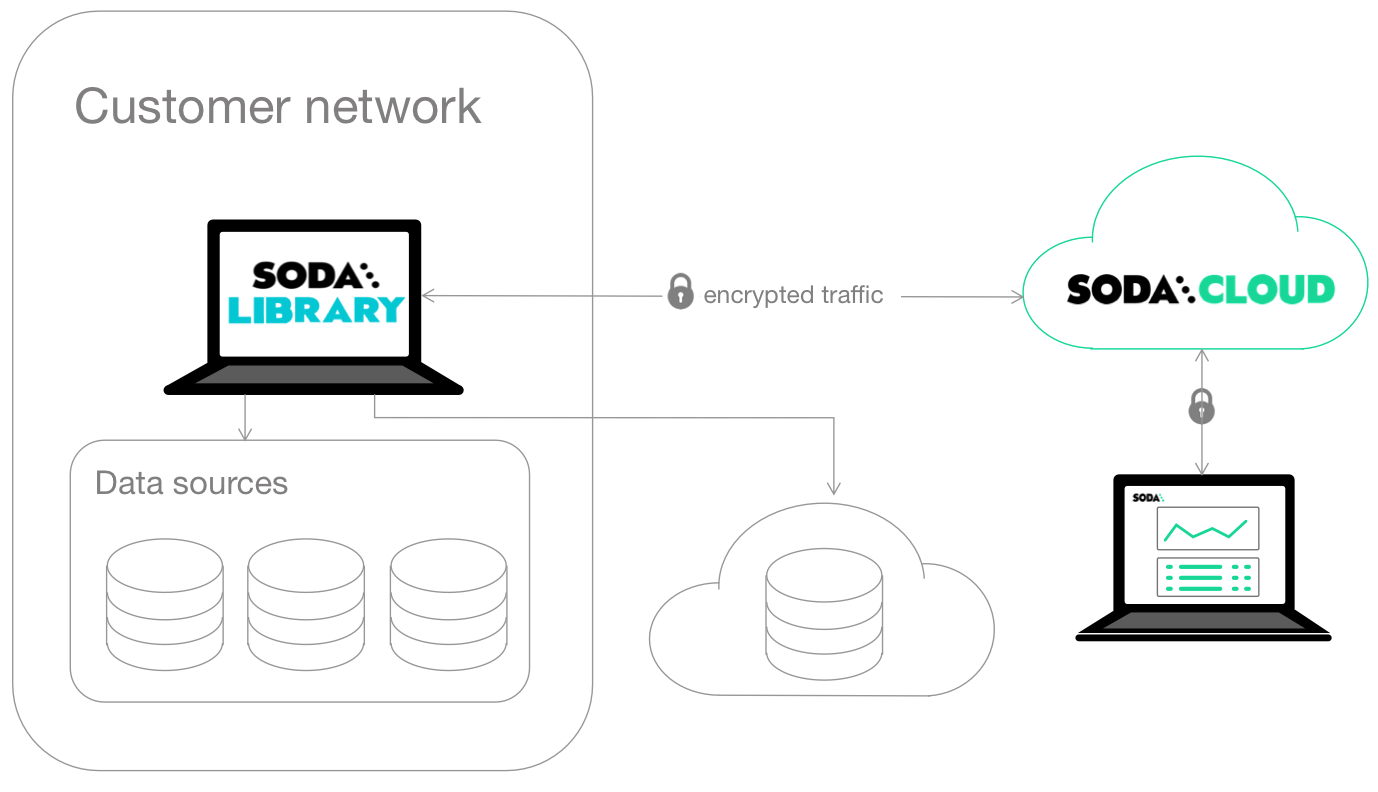
Self-operated deployment
Install Soda Library locally and connect it to Soda Cloud using API keys. Soda Library scans your datasets and pushes metadata to Soda Cloud. There, your team can view check results, collaborate on incidents, and integrate with tools like Slack.
By default, your data stays within your private network. See Data security and privacy (missing) for more details. To learn more about how to set up a self-operated deployment check out Self-operated deployment guide (missing)
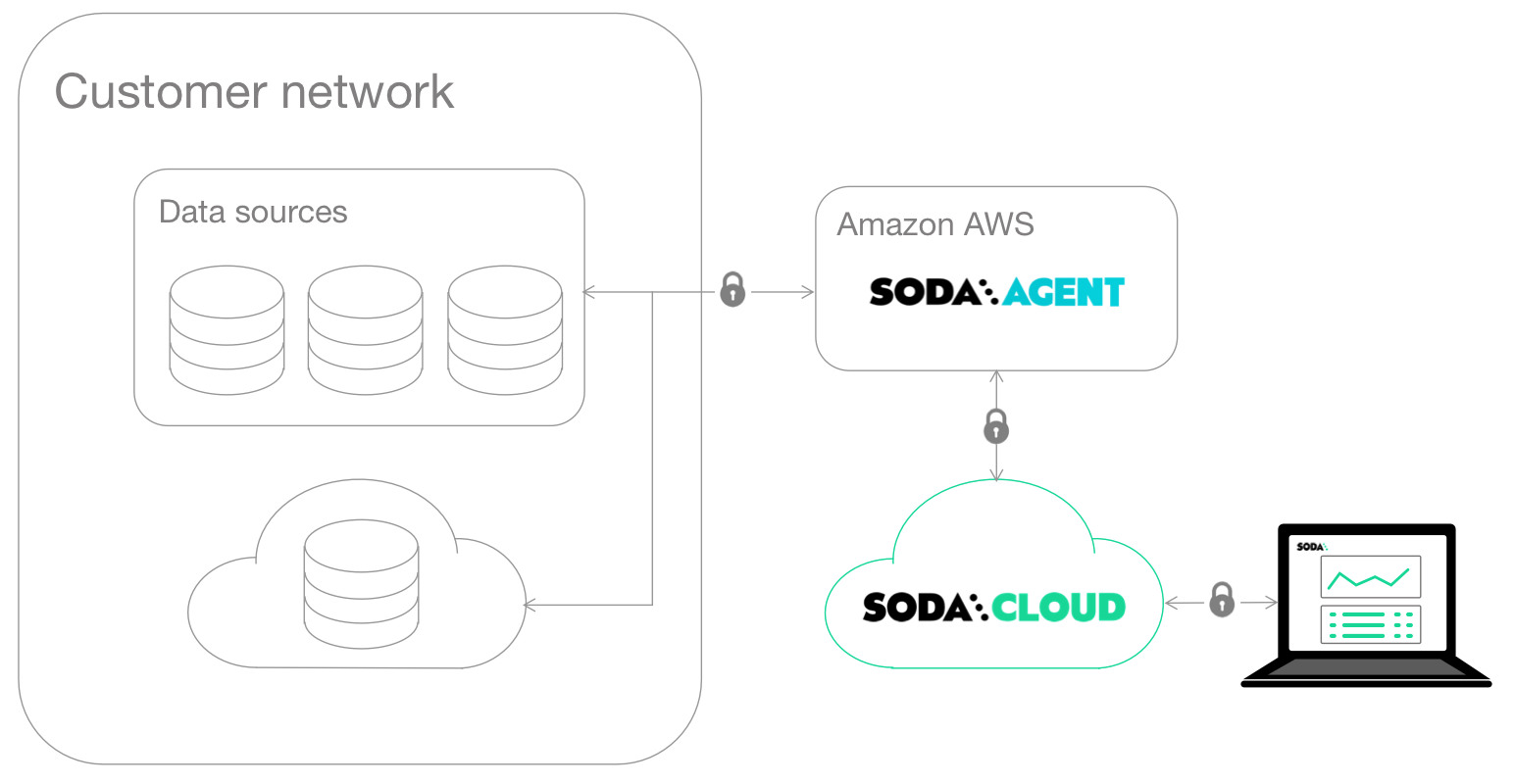
Soda-hosted deployment
Use Soda Cloud to connect directly to your data sources. Soda-hosted deployment gives you a secure, managed way to scan data, create no-code checks, and share insights—all from the UI.
This option supports BigQuery, Databricks SQL, MS SQL Server, MySQL, PostgreSQL, Redshift, and Snowflake. To learn more about how to set up a soda-hosted deployment check out Soda-hosted deployment guide (missing)
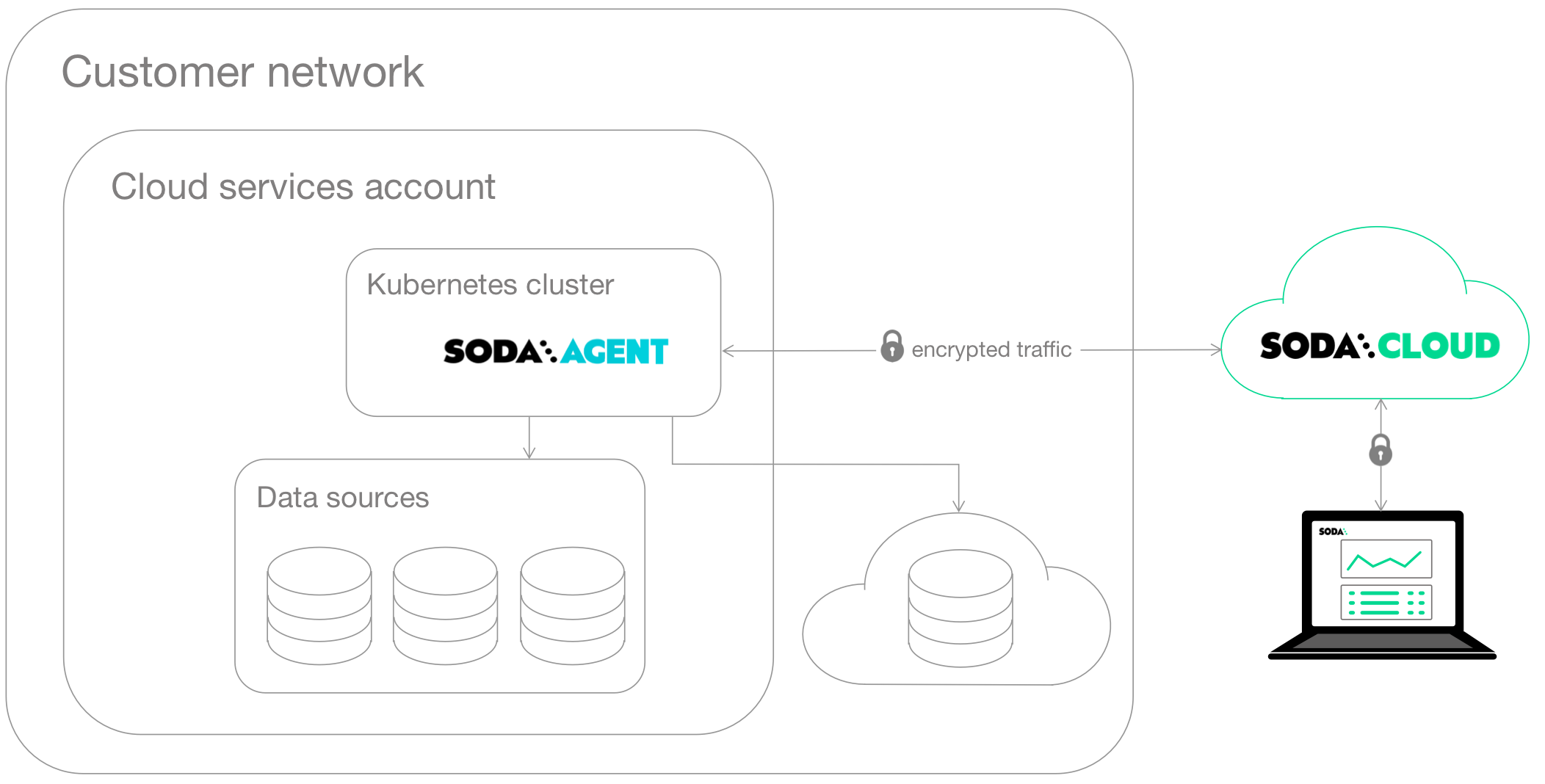
Self-hosted deployment
Run Soda Library inside your own Kubernetes cluster in AWS, Google Cloud, or Azure.
This deployment gives infrastructure teams full control over how Soda accesses data while still enabling Soda Cloud users to write and view checks. Checks can be written programmatically or through the UI. To learn more about how to set up a self-hosted deployment check out Self-hosted deployment guide (missing)
What’s Next?
To get started with Soda, follow one of these quickstarts based on your needs:
- Data testing quickstart: Learn how to define and run checks in your workflows.
- Data observability quickstart: Set up monitoring to detect anomalies in your datasets.